Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
使用
Begin
创建scrapy项目:
1 | scrapy startproject projectName |
创建爬虫文件
1 | cd projectName |
项目目录及文件
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
解析+持久化存储
基于终端指令的持久化存储
spiderBoss.py
1 | # -*- coding: utf-8 -*- |
项目启动
1 | scrapy crawl spiderBoss # 正常启动 |
基于终端指令的持久化存储
1 | scrapy crawl spiderBoss -o fileName # 用此命令启动就可实现基于终端指令的持久化存储 |
基于管道的持久化存储
spiderBoss.py
1 | # -*- coding: utf-8 -*- |
items.py
1 | # -*- coding: utf-8 -*- |
pipelines.py
1 | # -*- coding: utf-8 -*- |
settings.py
1 | # 解决中文乱码 |
启动
1 | scrapy crawl spiderBoss |
post请求
spider
1 | import scrapy |
scrapy的五大组件
Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。
调度器
调度器,说白了可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址(不做无用功)。用户可以跟据自己的需求定制调度器。
下载器
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
爬虫
爬虫,是用户最关心的部份。用户定制自己的爬虫,用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
实体管道
实体管道,用于处理爬虫提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
Scrapy引擎
Scrapy引擎是整个框架的核心。它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
Scrapy运行流程
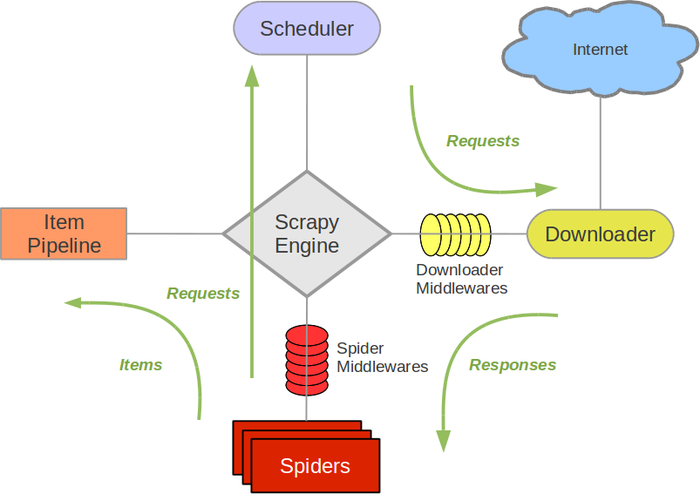
- 首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
- 然后,爬虫解析Response
- 若是解析出实体(Item),则交给实体管道进行进一步的处理。
- 若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
middleware
DOWNLOADER_MIDDLEWARES的使用
settings中放开注释
1 | DOWNLOADER_MIDDLEWARES = { |
middlewares.py
1 | # -*- coding: utf-8 -*- |
以参数形式传递 item
spider
1 | import scrapy |
item
1 | import scrapy |
Scrapy中selenium的使用
- 在spider的构造方法中创建一个浏览器对象(作为当前spider的一个属性)
- 重写spider的一个方法closed(self,spider),在该方法中执行浏览器关闭的操作
- 在下载中间件的process_response方法中,通过spider参数获取浏览器对象
- 在中间件的process_response中定制基于浏览器自动化的操作代码(获取动态加载出来的页面源码数据)
- 实例化一个响应对象,且将page_source返回的页面源码封装到该对象中
- 返回该新的响应对象
sipder
1 | import scrapy |
middleware
1 | from scrapy import signals |
提高scrapy的效率
不考虑的并发情况下,只需在settings的配置中如下:
1 | 增加并发: |
CrawlSpider
CrawlSpider也继承自Spider,所以具备它的所有特性.
参与过网站后台开发的应该会知道,网站的url都是有一定规则的。像django,在view中定义的urls规则就是正则表示的。那么是不是可以根据这个特性来设计爬虫,而不是每次都要用spider分析页面格式,拆解源码。回答是肯定的,scrapy提供了CrawlSpider处理此需求。
CrawlSpider类和Spider类的最大不同是CrawlSpider多了一个rules属性,其作用是定义”提取动作“。在rules中可以包含一个或多个Rule对象,在Rule对象中包含了LinkExtractor对象。
工程建立
1 | scrapy startproject projectName |
创建爬虫文件
1 | scrapy genspider -t crawl spiderName www.xxx.com |
爬虫文件如下
1 | # -*- coding: utf-8 -*- |
分布式爬虫
只用scrapy框架是没有办法做分布式的,因为,各个程序之间的数据是不能互通的,因此,要实现分布式爬虫,还需要使用scrapy-redis插件
spider爬虫文件,使用RedisCrawlSpider类替换之前的Spider类
1 | import scrapy |
settings
1 | ITEM_PIPELINES = { |
启动
1 | scrapy runspider 爬虫文件.py # 此时启动要启动.py |
此时在redis数据库端执行如下命令:
1 | redis-cli |
增量式爬虫
要实现增量式爬虫,一是在获得页面解析的内容后判断该内容是否已经被爬取过,二是在发送请求之前判断要被请求的url是否已经被爬取过,前一种方法可以感知每个页面的内容是否发生变化,能获取页面新增或者变化的内容,但是由于要对每个url发送请求,所以速度比较慢,而对网站服务器的压力也比较大,后一种无法获得页面变化的内容,但是因为不用对已经爬取过的url发送请求,所以对服务器压力比较小,速度比较快,适用于爬取新增网页
sipder
1 | # -*- coding: utf-8 -*- |
管道
1 | # -*- coding: utf-8 -*- |